
MySQL 字符集和排序规则
一、基本概念
1. 定义
- 字符集:一组符号和编码。
- 排序规则:一组用于比较字符集中字符的规则。
- MySQL 8.0 默认字符集为 utf8mb4,默认排序规则为 utf8mb4_0900_ai_ci。
2. 字符集与排序规则的关系
- CHARACTER SET 和 CHARSET 是同义词。
- 不同字符集的排序规则不同,每个字符集有默认排序规则。
- 排序规则的名称通常以字符集名称开头,然后跟一个后缀,以此区分不同的排序规则,如 utf8mb4_0900_ai_ci
二、排序规则详解
1. 命名规则
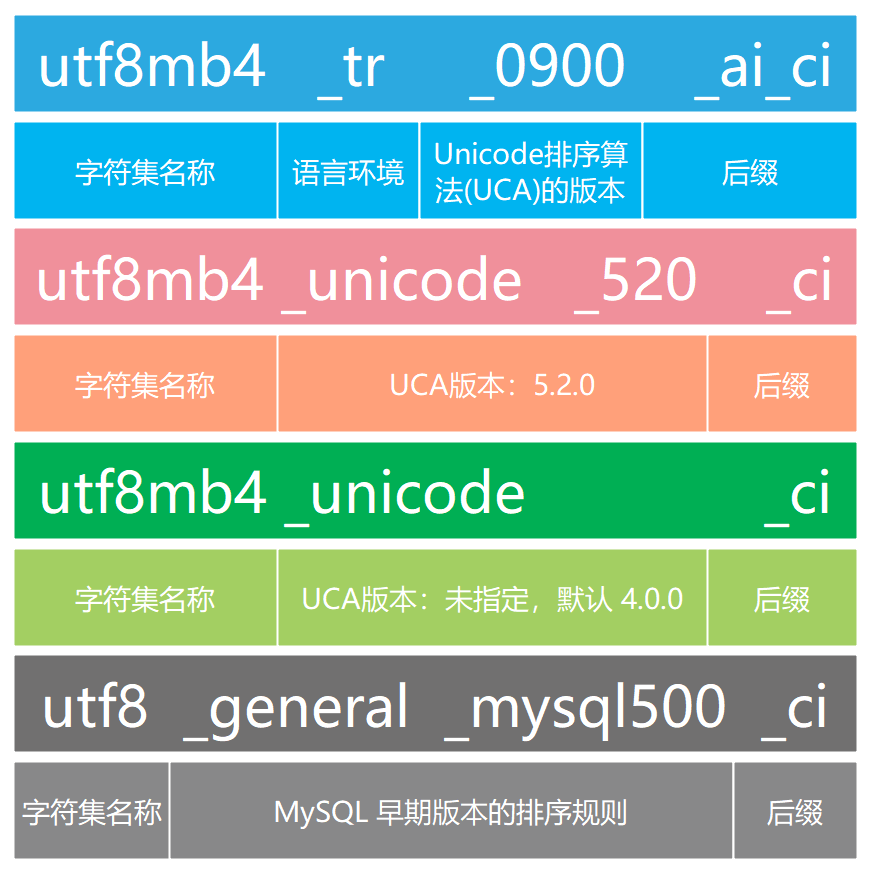
(1)语言相关
特定语言的排序规则含语言环境代码或名称,如 utf8mb4_tr_0900_ai_ci(tr 表示土耳其)。
(2)后缀含义
- _ai:Accent-insensitive(重音不敏感)
- _as:Accent-sensitive(重音敏感)
- _ci:Case-insensitive(大小写不敏感)
- _cs:Case-sensitive(大小写敏感)
- _ks:Kana-sensitive(假名敏感,区分日语片假名和平假名)
- _bin:Binary(二进制)
(3)关联规则
- 对于未指定重音敏感的非二进制排序规则,由大小写敏感确定,_ci 等价于 _ai,_cs 等价于 _as(如 latin1_general_ci 表示大小写和重音均不敏感)。
2. Unicode 字符集特殊规则
- 排序规则可含版本号,对应 Unicode 排序算法(UCA)版本,无版本号默认基于 UCA 4.0.0:
- utf8mb4_0900_ai_ci:基于 UCA 9.0.0
- utf8mb4_unicode_520_ci:基于 UCA 5.2.0
- utf8mb4_unicode_ci:基于 UCA 4.0.0
- xxx_general_mysql500_ci 保留 MySQL 5.1.24 前的排序顺序,用于兼容旧表升级。
三、字符集与排序规则的查看
1. SHOW 语句
-- 查看指定字符集(如 utf8 相关)
show character set where charset like 'utf8%';
-- 查看指定字符集的排序规则(如 utf8mb4)
show collation where charset = 'utf8mb4';
-- 查看所有字符集
show character set; -- 对应 INFORMATION_SCHEMA.CHARACTER_SETS
-- 查看所有排序规则
show collation; -- 对应 INFORMATION_SCHEMA.COLLATIONS
2. 信息表查询
-- 字符集信息
select * from information_schema.character_sets;
-- 排序规则信息
select * from information_schema.collations;
-- 数据库字符集信息
select * from information_schema.schemata;
四、各级别字符集与排序规则设置
1. 服务器级
(1)系统变量
- character_set_server:服务器字符集,默认 utf8mb4。
- collation_server:服务器排序规则,默认 utf8mb4_0900_ai_ci。
(2)设置方法
-
命令行启动时指定:
mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_0900_ai_ci -
修改配置文件(/etc/my.cnf):
[mysqld] character-set-server = utf8mb4 collation-server = utf8mb4_0900_ai_ci -
动态设置:
set global character_set_server=utf8mb4; set global collation_server=utf8mb4_0900_ai_ci; -
源码编译:
cmake . -DDEFAULT_CHARSET=latin1 -DDEFAULT_COLLATION=latin1_german1_ci
2. 数据库级
(1)系统变量
- character_set_database:数据库字符集,未指定则继承服务器级。
- collation_database:数据库排序规则,未指定则继承服务器级。
(2)设置方法
-- 创建数据库时指定
CREATE DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name];
-- 修改数据库设置
ALTER DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name];
示例:
create database zabbix character set utf8 collate utf8_general_ci;
alter database zabbix character set utf8mb4 collate utf8mb4_0900_ai_ci;
(3)选择规则
- 若均指定,使用指定值;
- 若仅指定其一,另一使用对应默认值(字符集对应默认排序规则,排序规则对应所属字符集);
- 若均未指定,继承服务器级。
3. 表级
(1)设置方法
-- 创建表时指定
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name];
-- 修改表设置
ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name];
示例:
create table t1(id int) character set utf8 collate utf8_general_ci;
(2)选择规则
未指定则继承数据库级。
4. 列级
(1)适用类型
CHAR、VARCHAR、TEXT、ENUM、SET 等字符列。
(2)设置方法
-- 创建表时指定列
col_name {CHAR | VARCHAR | TEXT} (col_length)
[CHARACTER SET charset_name]
[COLLATE collation_name];
-- 修改列设置
ALTER TABLE tbl_name MODIFY col_name {CHAR | VARCHAR | TEXT} (col_length)
[CHARACTER SET charset_name]
[COLLATE collation_name];
示例:
create table t2(id int, name varchar(10) character set utf8mb4 collate utf8mb4_0900_ai_ci);
alter table t2 modify name varchar(10) character set utf8 collate utf8_general_ci;
(3)选择规则
未指定则继承表级。
5. 字符串文字级
(1)系统变量
- character_set_connection:连接字符集,默认用于字符串文字。
- collation_connection:连接排序规则。
(2)设置方法
-- _charset_name 表达式,称为引入程序,它告诉解析器字符串所使用的字符集。引入程序在这里不会更改字符串,只是传递一个信号。
[_charset_name]'string' [COLLATE collation_name]
示例:
SELECT 'abc';
SELECT _latin1'abc';
SELECT _utf8mb4'abc' COLLATE utf8mb4_danish_ci;
(3)选择规则
- 仅指定排序规则:字符集使用 character_set_connection;
- 均未指定:使用 character_set_connection 和 collation_connection。
五、特殊字符集相关
1. 国家字符集
-
标准 SQL 中 NCHAR 或 NATIONAL CHAR 表示使用预定义字符集,MySQL 中预定义为 utf8。
-
等效表示:
CHAR(10) CHARACTER SET utf8; NATIONAL CHARACTER(10); NCHAR(10); -
字符串指定:
SELECT N'some text'; -- 推荐 SELECT _utf8'some text';
2. 字符集引入程序
-
用于指定字符串、十六进制或位值文字的字符集和排序规则:
[_charset_name] literal [COLLATE collation_name] -
注意:
- 字符串文字中,引入程序与字符串间可留空格;
- _binary 可指定二进制字符串,十六进制和位值文字默认二进制(可省略 _binary)。
六、元数据的字符集(UTF-8)
1. 存储规则
- 元数据必须使用统一字符集且包含所有语言字符,故 MySQL 用 Unicode(UTF-8)存储元数据。
否则,INFORMATION_SCHEMA 中表的 SHOW 语句和 SELECT 语句都将无法正常工作,因为这些操作结果的同一列中的不同行将使用不同的字符集。 - USER()、DATABASE() 等函数返回值默认字符集为 UTF-8。
2. 相关系统变量
- character_set_system:元数据字符集。
- character_set_results:查询结果字符集,默认 utf8mb4;设为 NULL 或 binary 时不转换元数据字符集。
七、连接字符集和排序规则
1. 核心系统变量
-
character_set_server, collation_server:服务器级别字符集和排序规则
-
character_set_database, collation_database:数据库级别字符集和排序规则
-
character_set_client:客户端发送语句的字符集。
-
character_set_connection/collation_connection:连接字符集和排序规则。服务器接收语句后转换的字符集和排序规则。
-
character_set_results:结果字符集。服务器返回结果(数据、元数据、错误消息)的字符集。如果不想对结果进行转换,可以将此变量设置为 NULL 或 binary。
SET character_set_results = NULL; SET character_set_results = binary;
2. 查看相关变量
-- 查看字符集相关变量
show variables like 'character_set%';
-- 查看排序规则相关变量
show variables like 'collation%';
-- 通过性能表查看
SELECT * FROM performance_schema.session_variables
WHERE VARIABLE_NAME IN (
'character_set_client', 'character_set_connection',
'character_set_results', 'collation_connection'
) ORDER BY VARIABLE_NAME;
+--------------------------+--------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+--------------------------+--------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_results | utf8mb4 |
| collation_connection | utf8mb4_0900_ai_ci |
+--------------------------+--------------------+
3. 客户端配置方法
(1)SET NAMES
同时设置客户端发送、服务器接收转换、结果返回的字符集:
SET NAMES 'charset_name' [COLLATE 'collation_name'];
-- 等效于
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET character_set_connection = charset_name;
(2)SET CHARACTER SET
设置客户端发送和结果返回字符集,服务器接收转换使用数据库级规则:
SET CHARACTER SET 'charset_name';
-- 等效于
SET character_set_client = charset_name;
SET character_set_results = charset_name;
SET collation_connection = @@collation_database;
(3)配置文件
[mysql]
default-character-set=koi8r
八、应用与转换
1. 字符集应用示例
(1)建库指定
CREATE DATABASE mydb
CHARACTER SET latin1
COLLATE latin1_swedish_ci;
(2)启动配置
[mysqld]
character-set-server=latin1
collation-server=latin1_swedish_ci
(3) 源码构建,在配置时指定
不需要使用 SET NAMES 配置连接。
cmake . -DDEFAULT_CHARSET=latin1 \
-DDEFAULT_COLLATION=latin1_swedish_ci
(4)Web 页面设置
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
2. 列字符集转换
(1)单列表转换
ALTER TABLE t MODIFY col1 VARCHAR(50) CHARACTER SET greek;
-- 二进制转字符型后移除末尾 0x00
UPDATE t SET col1 = TRIM(TRAILING 0x00 FROM col1);
(2)更改表中所有列的字符集
ALTER TABLE t2 CONVERT TO CHARACTER SET utf8mb4;
九、错误消息的字符集
1. 构造规则
- 消息模板使用 UTF-8(utf8mb3);
- 参数替换规则:标识符用 UTF-8,非二进制字符串转 UTF-8,二进制字符串特殊字节用十六进制编码。
2. 处理规则
- 写入错误日志:直接用 UTF-8;
- 发送到客户端:转换为 character_set_results 指定字符集,无法表示的字符用 Unicode 代码点编码。
十、MySQL 服务器的语言环境支持
1. 系统变量
- lc_time_names:控制日期、月份名称的显示语言,默认 en_US,支持 zh_CN、ja_JP 等(参考 IANA 语言标签)。
2. 受影响的函数
DATE_FORMAT()、DAYNAME()、MONTHNAME(),名称会从 utf8 转换为 character_set_connection 字符集。
示例:
mysql> SET NAMES 'utf8';
Query OK, 0 rows affected (0.09 sec)
mysql> SELECT @@lc_time_names;
+-----------------+
| @@lc_time_names |
+-----------------+
| en_US |
+-----------------+
1 row in set (0.00 sec)
mysql> SELECT DAYNAME('2010-01-01'), MONTHNAME('2010-01-01');
+-----------------------+-------------------------+
| DAYNAME('2010-01-01') | MONTHNAME('2010-01-01') |
+-----------------------+-------------------------+
| Friday | January |
+-----------------------+-------------------------+
1 row in set (0.00 sec)
mysql> SELECT DATE_FORMAT('2010-01-01','%W %a %M %b');
+-----------------------------------------+
| DATE_FORMAT('2010-01-01','%W %a %M %b') |
+-----------------------------------------+
| Friday Fri January Jan |
+-----------------------------------------+
1 row in set (0.00 sec)
mysql> SET lc_time_names = 'es_MX';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@lc_time_names;
+-----------------+
| @@lc_time_names |
+-----------------+
| es_MX |
+-----------------+
1 row in set (0.00 sec)
mysql> SELECT DAYNAME('2010-01-01'), MONTHNAME('2010-01-01');
+-----------------------+-------------------------+
| DAYNAME('2010-01-01') | MONTHNAME('2010-01-01') |
+-----------------------+-------------------------+
| viernes | enero |
+-----------------------+-------------------------+
1 row in set (0.00 sec)
mysql> SELECT DATE_FORMAT('2010-01-01','%W %a %M %b');
+-----------------------------------------+
| DATE_FORMAT('2010-01-01','%W %a %M %b') |
+-----------------------------------------+
| viernes vie enero ene |
+-----------------------------------------+
1 row in set (0.00 sec)
3. 不受影响的函数
STR_TO_DATE()、GET_FORMAT()、FORMAT()(FORMAT() 可通过第三个参数指定语言环境)。
十一、配置与限制
1. 配置选项
- –character-set-server:服务器字符集;
- –collation-server:服务器排序规则;
- –character-sets-dir:字符集目录。
2. 限制
- 标识符仅支持 UTF-8 基本多语言面(BMP)字符;
- ucs2、utf16 等字符集不可作客户端字符集,不支持 LOAD DATA 加载其数据文件;
- REGEXP 和 RLIKE 按字节比较,多字节字符集可能有意外结果。