
MySQL 存储引擎详解
一、存储引擎概述
MySQL 的存储引擎是处理数据的底层软件组件,它决定了表的存储方式、索引结构、事务支持、锁粒度等核心特性。与其他数据库(如 Oracle 仅支持一种引擎)不同,MySQL 支持插件式存储引擎,且存储引擎是表级别的——同一数据库中不同表可根据需求选择不同引擎,这一特性使其具备极高的灵活性。
存储引擎的选择直接影响数据库的性能、可靠性和功能支持,需结合业务场景(如事务需求、并发量、读写比例等)综合决策。
二、核心存储引擎
1. InnoDB(MySQL 5.5+ 默认引擎)
InnoDB 是为事务处理、高并发写操作和数据完整性设计的引擎,是生产环境中最常用的选择。
核心特性
- 事务支持:完全遵循 ACID 原则,支持事务提交(COMMIT)、回滚(ROLLBACK),可通过
SET AUTOCOMMIT=0手动控制事务。 - 行级锁:仅锁定修改的行(通过索引条件查询时),大幅提升高并发性能;若未使用索引,则退化为表锁。
- 外键约束:支持 FOREIGN KEY,强制数据参照完整性(如父子表关联)。
- MVCC(多版本并发控制):通过版本链实现“读不加锁、读写不冲突”,支持四种事务隔离级别(默认:可重复读 REPEATABLE READ)。
- 聚簇索引:主键索引与数据行存储在一起,二级索引指向主键;若无主键,自动生成隐藏的 6 字节行 ID 作为聚簇索引。
- 崩溃恢复:通过 redo 日志(重做日志)和 undo 日志(回滚日志)实现崩溃后的数据恢复,保证数据不丢失。
- 自适应哈希索引:自动为频繁访问的索引构建哈希索引,提升查询速度(无需手动配置)。
- 表空间管理:
- 独立表空间(默认):每张表对应
xxx.ibd文件(由innodb_file_per_table=ON控制),支持单表备份和迁移。 - 共享表空间:所有表的数据/索引存储在
ibdata1等文件中(易膨胀,不推荐)。
- 独立表空间(默认):每张表对应
适用场景
- 电商订单、金融交易等需要事务和数据完整性的核心业务表;
- 高并发写操作(如秒杀、库存更新);
- 需要外键约束的场景。
2. MyISAM(MySQL 5.5 前默认引擎)
MyISAM 是为只读/读多写少、无事务需求设计的轻量级引擎,目前已逐渐被 InnoDB 替代。
核心特性
- 无事务支持:所有操作自动提交,数据修改后无法回滚。
- 表级锁:修改表时锁定整张表(读锁/写锁互斥),高并发写场景下性能极差(写操作会阻塞所有读)。
- 全文索引:MySQL 5.6 前仅 MyISAM 支持全文索引(InnoDB 5.6+ 已支持)。
- 存储文件:每张表对应 3 个文件——
xxx.frm(表结构)、xxx.MYD(数据)、xxx.MYI(索引)。 - 快速 COUNT(*):内置表行数统计,无需扫描全表(InnoDB 需扫描全表或依赖覆盖索引)。
- 崩溃恢复差:无崩溃恢复机制,数据损坏后需通过
myisamchk工具手动修复。 - 不支持外键:无法强制数据参照完整性。
适用场景
- 只读/读多写少的场景(如日志表、静态配置表);
- 临时统计报表(需快速
COUNT(*)); - 无需事务、外键的简单场景(逐步被 InnoDB 替代)。
三、其他常用存储引擎
1. MEMORY(HEAP)
- 特性:数据完全存储在内存中,重启 MySQL 后丢失;默认使用哈希索引(查询快但不支持范围查询);表级锁,并发性能差;不支持 BLOB/TEXT 类型。
- 适用场景:临时缓存表(如会话数据、临时计算结果)、高频访问的静态数据(如字典表)。
2. CSV
- 特性:数据以纯文本 CSV 文件存储(
xxx.csv),可直接用文本编辑器修改;无索引,查询需扫描全表;支持跨平台数据交换。 - 适用场景:数据导入/导出(如批量导入历史数据)、与外部系统的简单数据交互。
3. ARCHIVE
- 特性:专为归档设计,高压缩比;仅支持 INSERT 和 SELECT,不支持更新/删除;无索引,查询性能差。
- 适用场景:日志归档(如服务器访问日志)、历史数据存储(如几年前的订单记录)。
4. BLACKHOLE(黑洞引擎)
- 特性:写入的数据会被丢弃,读取时返回空结果,无实际存储。
- 适用场景:主从复制的中继节点(仅转发日志,不存储数据)、测试环境(验证写入逻辑)。
5. MERGE
- 特性:将多个结构相同的 MyISAM 表合并为一个逻辑表,简化分表后的查询。
- 适用场景:分表后的批量查询(如按年份拆分的日志表,合并后统一查询)。
四、核心引擎对比表
| 特性 | InnoDB | MyISAM | MEMORY | CSV |
|---|---|---|---|---|
| 事务支持 | 支持(ACID) | 不支持 | 不支持 | 不支持 |
| 锁粒度 | 行级锁(索引条件) | 表级锁 | 表级锁 | 表级锁 |
| 外键约束 | 支持 | 不支持 | 不支持 | 不支持 |
| 崩溃恢复 | 支持(redo/undo 日志) | 不支持(需手动修复) | 不支持(内存丢失) | 不支持(纯文本) |
| 索引类型 | 聚簇索引+二级索引 | 非聚簇索引 | 哈希索引(默认) | 无索引 |
| COUNT(*) 速度 | 慢(需扫描) | 快(内置统计) | 快(内存) | 慢(扫描全表) |
| 数据持久化 | 支持 | 支持 | 不支持(重启丢失) | 支持(纯文本) |
| 适用场景 | 事务/高并发写 | 读多写少/无事务 | 临时缓存 | 数据导入导出 |
五、InnoDB 架构
InnoDB 架构围绕“内存缓冲 + 磁盘持久化”设计,核心是通过内存减少磁盘 IO 开销,通过日志和特殊机制保证数据可靠性。
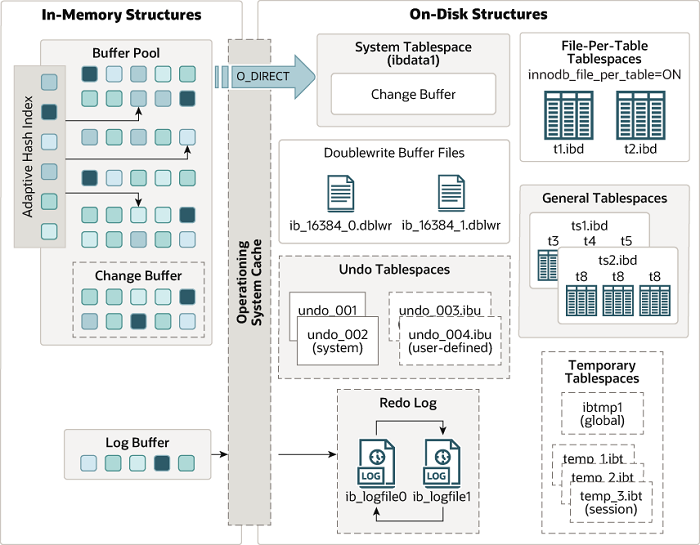
1. 内存架构
(1)缓冲池(Buffer Pool)
InnoDB 最核心的内存区域(占 MySQL 内存的 70%~80%,由 innodb_buffer_pool_size 控制),缓存表数据页、索引页、Undo 日志、变更缓冲等。
- 管理机制:
- LRU 链表(改进版):分“年轻区”和“年老区”,新页插入到链表 3/8 位置,避免全表扫描刷爆热点数据。
- 刷新列表(Flush List):记录“脏页”(内存修改未刷盘的页),后台线程定期刷盘。
- 缓冲池实例:拆分多个实例(
innodb_buffer_pool_instances),减少锁竞争。
(2)重做日志缓冲(Redo Log Buffer)
临时存储 redo 日志,避免每次事务提交直接写磁盘,由 innodb_log_buffer_size 控制(默认 16MB)。刷盘时机:事务提交时、每秒自动刷盘、缓冲池满时。
(3)其他辅助结构
- 变更缓冲(Change Buffer):缓存非聚簇索引的 DML 操作,待数据页加载到缓冲池时批量合并,减少磁盘随机 IO。
- 自适应哈希索引(AHI):自动为频繁访问的索引构建哈希索引,提升等值查询性能。
- 锁结构/事务系统:存储锁信息、事务 ID、读视图(MVCC 基础)等。
2. 磁盘架构
(1)表空间
| 类型 | 文件 | 存储内容 | 特性 |
|---|---|---|---|
| 系统表空间 | ibdata1 |
数据字典、双写缓冲区、早期 Undo 日志 | 8.0 后拆分 Undo/临时表空间,减少碎片 |
| 独立表空间 | xxx.ibd |
单表数据+索引 | 默认开启(innodb_file_per_table=1) |
| 通用表空间 | 手动创建的表空间文件 | 可存放多个表 | 支持跨表共享 |
| Undo 表空间 | undo_001、undo_002 |
Undo 日志 | 8.0 支持在线扩容/收缩 |
| 临时表空间 | ibtmp1 |
临时表数据 | 重启后清空 |
(2)核心日志文件
- redo log(ib_logfile0、ib_logfile1):记录数据页的物理修改,保证事务持久性,循环写入。
- undo log(存于 Undo 表空间):记录事务修改前的状态,支持回滚和 MVCC(插入 Undo 提交后删除,更新 Undo 保留到快照过期)。
(3)辅助结构
- 双写缓冲区(Doublewrite Buffer):刷脏页时先写双写缓冲区,再写数据页,解决“页部分写”问题,崩溃时可恢复完整页。
- 数据字典:8.0 后存于系统表空间,记录表结构、索引等元数据。
3. 后台线程
- 主线程(Master Thread):协调刷脏页、合并变更缓冲、刷 redo log 等。
- 刷新脏页线程:并行刷脏页,减少主线程压力。
- 日志写入线程:将 redo log 缓冲刷到磁盘。
- Purge 线程:清理过期 Undo Log,提升空间利用率。
- 检查点线程:触发检查点,刷脏页到磁盘,减少崩溃恢复时间。
4. 核心机制
- ACID 实现:
- 原子性:依赖 Undo Log 回滚事务;
- 一致性:通过原子性、持久性、隔离性保证;
- 隔离性:行锁 + MVCC 实现;
- 持久性:依赖 Redo Log 刷盘。
- MVCC:通过每行隐藏列(
DB_TRX_ID、DB_ROLL_PTR)和读视图,实现多版本数据读取,避免读锁。 - 两阶段提交(2PC):协调 Redo Log 和 Binlog 一致性,分 Prepare(写 Redo Log)和 Commit(写 Binlog 并标记 Redo Log 为提交)阶段。
- 崩溃恢复:重放检查点后的 Redo Log 恢复已提交数据,通过 Undo Log 回滚未提交事务。
六、存储引擎操作
1. 查看支持的存储引擎
SHOW ENGINES; -- "Support" 列:YES(支持)、DEFAULT(默认)、NO(不支持)
2. 查看指定表的存储引擎
-- 方法1:查看建表语句
SHOW CREATE TABLE `table_name`;
-- 方法2:查询数据字典
SELECT TABLE_NAME, ENGINE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'db_name' AND TABLE_NAME = 'table_name';
3. 设置默认存储引擎
修改配置文件(my.cnf/my.ini),重启生效:
[mysqld]
default-storage-engine = InnoDB
innodb_file_per_table = ON # 启用InnoDB独立表空间
4. 创建表时指定引擎
CREATE TABLE `user` (
`id` INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
5. 修改表的存储引擎
ALTER TABLE `table_name` ENGINE = MyISAM;
Note:InnoDB 改 MyISAM 会丢失外键和事务特性,需提前备份。
七、存储引擎选择原则
- 优先选 InnoDB:90%+ 业务场景(事务、高并发、数据完整性);
- MyISAM:仅用于读多写少、无事务、需快速
COUNT(*)的场景(逐步淘汰); - MEMORY:临时缓存、高频访问的静态数据;
- CSV:跨平台数据交换;
- ARCHIVE:日志归档、历史数据存储;
- BLACKHOLE:测试/主从中继。
八、注意事项
- InnoDB 行锁:仅通过索引条件查询时触发行锁,否则为表锁;
- MyISAM 并发:写操作阻塞所有读,读操作阻塞写,高并发写场景禁用;
- MEMORY 数据丢失:仅适合临时数据,不可存储核心业务数据;
- 存储引擎与索引:不同引擎索引实现差异大(如 InnoDB 聚簇索引 vs MyISAM 非聚簇索引),需结合引擎设计索引;
- 迁移建议:老系统的 MyISAM 表建议逐步迁移到 InnoDB(通过
ALTER TABLE或数据导出/导入)。